Abstract
Video-to-video translation aims to generate video frames of a target domain from an input video.
Despite its usefulness, the existing video-to-video translation methods require enormous computations, necessitating their model compression for wide use.
While there exist compression methods that improve computational efficiency in various image/video tasks, a generally-applicable compression method for video-to-video translation has not been studied much.
In response, this paper presents Shortcut-V2V, a general-purpose compression framework for video-to-video translation.
Shortcut-V2V avoids full inference for every neighboring video frame by approximating the intermediate features of a current frame from those of the preceding frame.
Moreover, in our framework, a newly-proposed block called AdaBD adaptively blends and deforms features of neighboring frames, which makes more accurate predictions of the intermediate features possible.
We conduct quantitative and qualitative evaluations using well-known video-to-video translation models on various tasks to demonstrate the general applicability of our framework.
The results show that Shoutcut-V2V achieves comparable performance compared to the original video-to-video translation model while saving 3.2-5.7x computational cost and 7.8-44x memory at test time.
Pipeline
In this paper, we propose Shortcut-V2V, a general compression framework to improve the test-time efficiency in video-to-video translation.
As illustrated in Figure 1.(a), given {It}NT-1t=0 as input video frames, we first use full teacher model T to synthesize the output of the first frame.
Then, for the next frames, our newly-proposed Shortcut block efficiently approximates ft, the features from the ld-th decoding layer of the teacher model.
This is achieved by leveraging the le-th-th encoding layer features at along with reference features, aref and fref, from the previous frame.
Here, ld and le correspond to layer indices of the teacher model.
Lastly, predicted features f̂t are injected into the following layers of the teacher model to synthesize the final output Ôt.
To avoid error accumulation, we conduct full teacher inference and update the reference features at every max interval α.
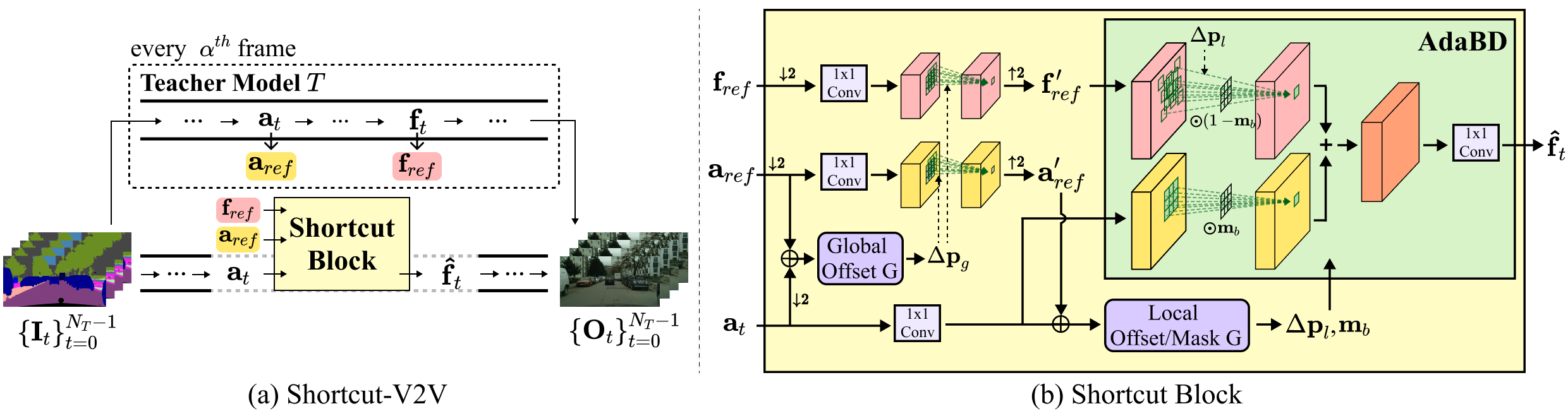
Figure 1. Overview of the proposed ShortCutV2V. (a) is an overall architecture of Shorcut-V2V, and (b) shows a detailed architecture of Shortcut block.
